
Aktuelles

Faire und verlässliche Sprachverarbeitung
Seit September 2025 ist Vagrant Gautam als Independent Postdoc am HITS. Mit dem Independent Postdoc Programm erhalten junge Forschende die Möglichkeit, …

Papier bei der ACL 2022 akzeptiert!
Ein Papier von Doktorand Sungho Jeon und NLP-Gruppenleiter Michael Strube wurde für die diesjährige ACL akzeptiert, welches eine der …
HITS NLP goes Linguistik!
Mitglieder der HITS NLP-Gruppe werden zwei Vorträge auf dem Workshop Word formation and discourse structure am Institut für Germanistik …
NeurIPS 2021 Paper akzeptiert!
Federico López, Doktorand der NLP-Gruppe, ist der erste Autor eines Papiers, welches als spotlight paper auf der diesjährigen&…

Papier akzeptiert bei LAW 2020
Das Papier “pyMMAX2: Deep Access to MMAX2 Projects from Python” von Mark-Christoph Müller wurde als Poster für LAW, den …
Papier akzeptiert auf SDP-Workshop
Das Papier „Reconstructing Manual Information Extraction with DB-to-Document Backprojection: Experiments in the Life Science Domain“ von Mark-Christoph Müller, Sucheta Ghosh, …
Zwei EMNLP-Papiere akzeptiert
Das Papier „A Centering Approach for Discourse Structure-aware Coherence Modeling“ von Sungho Jeon, Doktorand und HITS-Stipendiat in der NLP-Gruppe, und Michael …

HITS-Wissenschaftler Michael Strube neuer Fellow der ACL
Michael Strube, Leiter der Forschungsgruppe “Natural Language Processing” am Heidelberger Institut für Theoretische Studien (HITS), ist zum Fellow der “Association …
“Best Poster and Demonstration Award” für NLP-Wissenschaftler am HITS
Mark-Christoph Müller aus der Gruppe „Natural Language Processing“ (NLP) am HITS wurde bei der “23rd International Conference on Theory and …
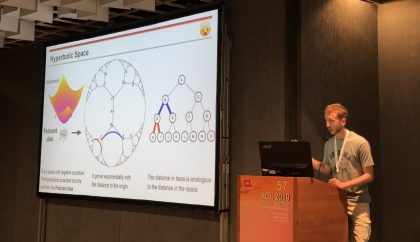
„Best Paper Award“ für HITS-Computerlinguisten
Federico López und Michael Strube, beide Mitglieder der Natural Language Processing (NLP) Gruppe am HITS, sowie Benjamin Heinzerling (HITS alumni) …